Data is everywhere. From cosmology to public health, interested parties measure and tabulate descriptive features of processes and objects that they want to understand. Implicit in this activity is the hope (or in less emotional terms, the assumption) that in this cacophony of description there are relationships, or principles, that explain what is observed. For our purposes here to “explain” a set of data is to functionally relate all or a subset of that data (the inputs) to a another set of of data (the outputs). From this definition there remain a few questions, perhaps most pressing is how do we select this functional relationship? Or even how does one know what data to functionally relate with respect to other data? More esoterically one could even query what it means to “functionally relate” at all, and what constitutes a good versus a bad explanation? I think all of these are interesting, but will address none of them here. Instead what I aim to describe is how to select the best functional relationship once a class of functional relationships (i.e. a model) is selected and given a clear idea of what variables constitute the data subset which intends to explain the output data of interest. In much simpler terms, what does it mean to “fit” a model to data?
All non-trivial models have parameters which dictate how inputs are mapped or transformed to yield outputs. A linear function, 

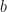

To address these issues we need a more sophisticated strategy for searching through parameter space. In general this presents as an optimization problem, where some “objective function” is either minimized or maximized. An objective function is a function that relates relevant variables (e.g. data recordings and model predictions) onto a value that represents a desired objective. In the context of model fitting, this objective function is parameterized by characteristics of the model, like the predictions those parameters determine or even the sum total of the parameter values of the model. Indeed an objective function can be constrained as desired in order to shape which model parameterizations are deemed best.
Now we are equipped to move through an example. In my experience, I first ran across “model fitting” in a statistics course via linear regression. I view this as a good starting point for introducing model fitting. So let’s begin there. Often the type of regression most are familiar with is least-squares linear regression. In least-squares regression for some arbitrary input data x data and outputs 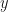
Here we have a great example of an objective function! We have a function that represents a measure of a model’s fit to the data in through a comparison between the predictions the model makes and the actual output data observations. The squaring of the error, or the difference between the actual and predicted y values, is necessary to avoid negative values. One could imagine avoiding negative values by simply taking the absolute value of the errors, but this would present problems during optimization later on [1].

For simplicity in notation, I have packaged the linear model parameters into a set denoted by 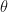

This is a great approach, and intuitively seems to make a lot of sense. For a line to represent your data, you’d want that line to be as close as it can be to all the data points; minimizing the average squared distance from the data points to the line should accomplish this.
As it turns out, least squares can be seen as a special case of a more general approach to model fitting: maximum likelihood estimation (MLE). In MLE model fitting, parameters (slope and intercept in the case of linear regression) are estimated such that the probability of observing the data at hand (called the “likelihood”) is maximized. In other words, the more “likely” it is for a given choice of parameter values to produce the data that we observed, the more we favor those parameter values.
This all sounds great, but we still do not have a complete picture of what “likely” means. To address this we take the stance that the model we seek to fit represents the true, ideal relationship between input data and output observations, and the observed variability of this input-output relationship is due to noise. Another way to think about this is if we take a slice of our output data, at some x value, the observed outputs can be considered to be drawn from a probability distribution.

Figure 1: At left we have some fake data with a least-squares linear model fit. Example residuals are shown in black. At right we see how conditioning on an x-value we can view our observed output data as a random variable.
Here we now start to see the route towards maximizing likelihood. What we would like to do is to find the parameters for the probability distribution (e.g. the Gaussian distribution) that yields a distribution that would generate the observed data with the highest probability. We will need to do this conditioned on each x-value. The expectation value of this probability distribution (i.e. the average) represents the model prediction for that particular x-value. In our figure this means that the peak of the gaussian curve at right maps onto the point on the red line predicting an output for an x-value of 
First let’s define our likelihood function. Let’s call it 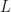
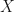
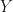


Now because we aren’t just interested in calculating the likelihood for some arbitrary parameters

Let’s cast our attention to the probability term on the right hand side of the log-likelihood equation. We have already discussed how to determine this probability. As discussed earlier, we are assuming that each output data y-value is sampled from a Gaussian distribution conditioned on the input data x-value. The equation describing a generic Gaussian distribution is the following:

where 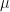
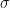

So we can plug this in for the

Putting all of this together we have worked our way to our full log-likelihood equation!

This is the function for which we want to find the parameters 

This brings us close to the end, but in closing I would like to show how this formulation of linear regression reduces to the special case of least-squares linear regression that most are familiar with. The approach we will take to do this is investigate our likelihood function and identify components that do not change if a different model (i.e. different parameter set) is tested. So we are looking for parts of the function that do not depend on our 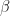

But the log serves now to simply cancel the exponential. Additionally we can remove the the sigma in the denominator of the exponential and the leading term in the sum as they are both terms that do not depend on the model parameters. All of this leaves us with the following:

Minimizing this new formulation is equivalent to the least-squares approach to linear regression.
Maximum-likelihood is important to understand because it is more general than the commonly encountered least-squares approach and is thus applicable to more settings where, for example, different assumptions are made about the output data measurement noise distribution. Secondly, I find that posing the problem in terms of the likelihood function is an interesting twist because doing so takes the stance that there is a relationship between input and output data that accounts both for explainable and unexplainable aspects of (measurement noise) the input-output relationship. In our linear regression example, the output data is taken to be a linear function of the input data, plus some noise which remains unexplained (beyond assuming a particular noise probability distribution). To me this has strong ties to philosophy of science and perhaps even epistemology. For example, if we consider a model, like our linear model, to represent knowledge about relationships between measured entities then the MLE model fitting approach proposes a formal strategy for how knowledge manifests and its explainable and unexplainable facets. This line of thinking spawns new questions related to those posited in the introductory paragraph. Namely, how are the model parameterizations and sets of input and output data measurements selected so as to fit meaningful models and thus establish knowledge? I am admittedly not supremely confident in a 1:1 mapping of knowledge onto statistical models, but at the very least I see model fitting as a mathematical formalism capable of discussing the topic of knowledge. I intend in future posts to continue exploring this kind of relationship between mathematical formalism of model fitting and more philosophical questions of knowledge and the scientific method.
[1] This is because performing optimization on an objective function like we have here requires taking the derivative of the objective function. The squared error is everywhere differentiable, while the absolute error is not (its derivative is undefined at 0). This makes the squared error more amenable to optimization.
[2] Through inspection we can see this is the case as setting
